打开任意一个应用时,AI各类应用会出现两类界面,如图1、图2所示。图1可以通过输入相关参数获得运行后的结果,运行方式包括单次运行和批量运行,关于如何批量运行后文会详细介绍。图2是在具体场景中以对话的形式展开,点开需要先与AI发一个对话才能继续。
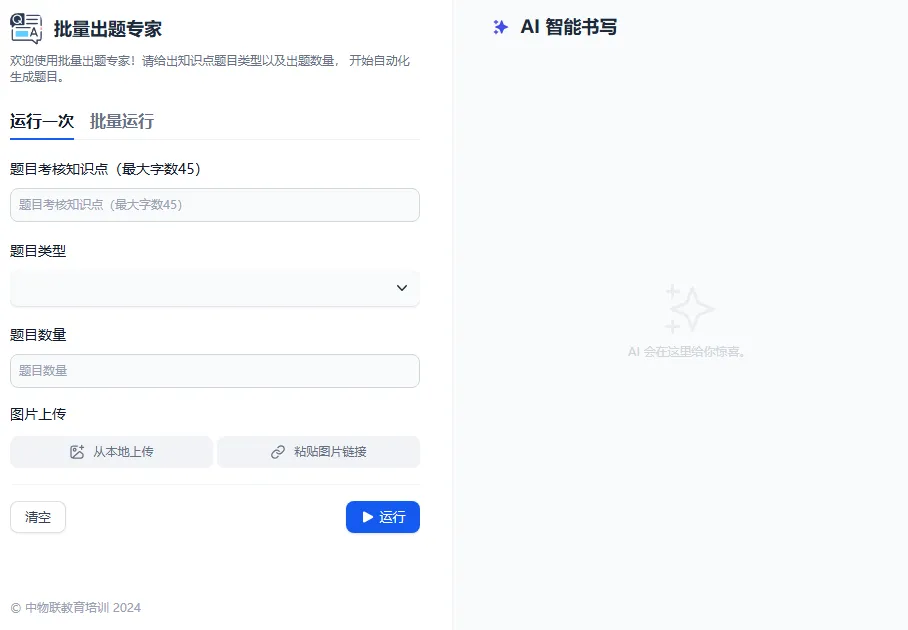
图1 批量出题专家应用界面
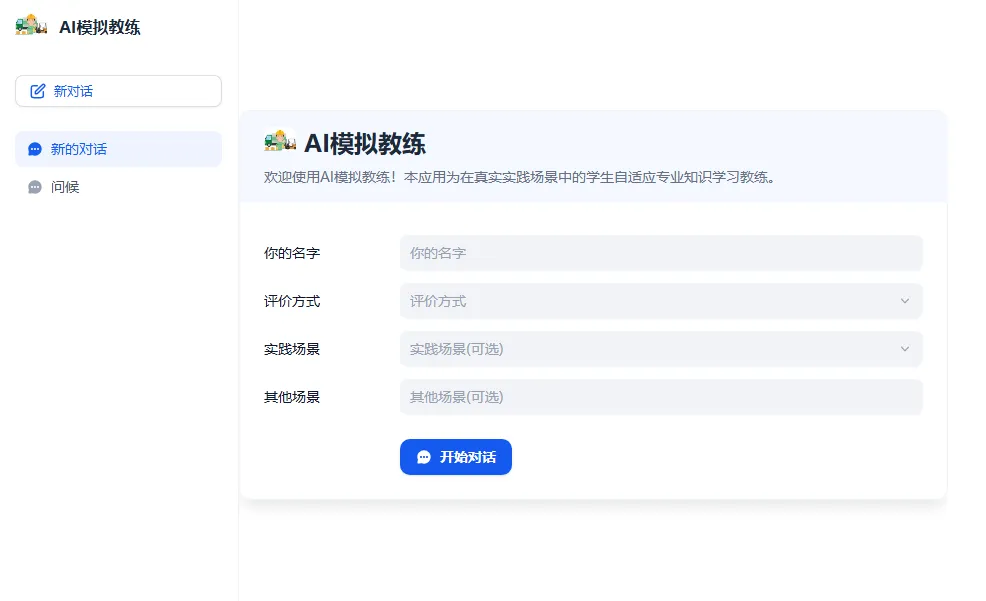
图2 AI模拟教练
批量运行操作指南
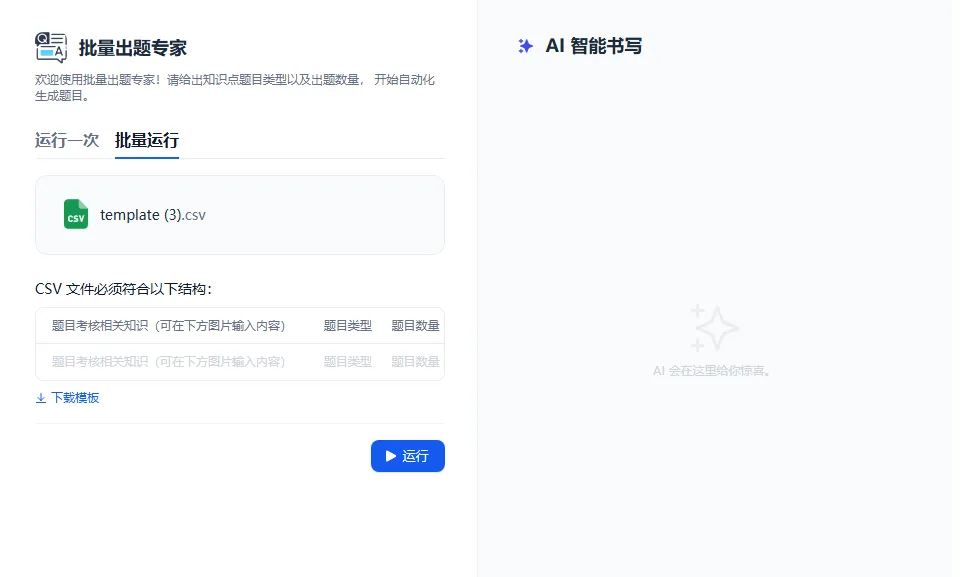
1、将页面切换至“批量运行”界面,如下图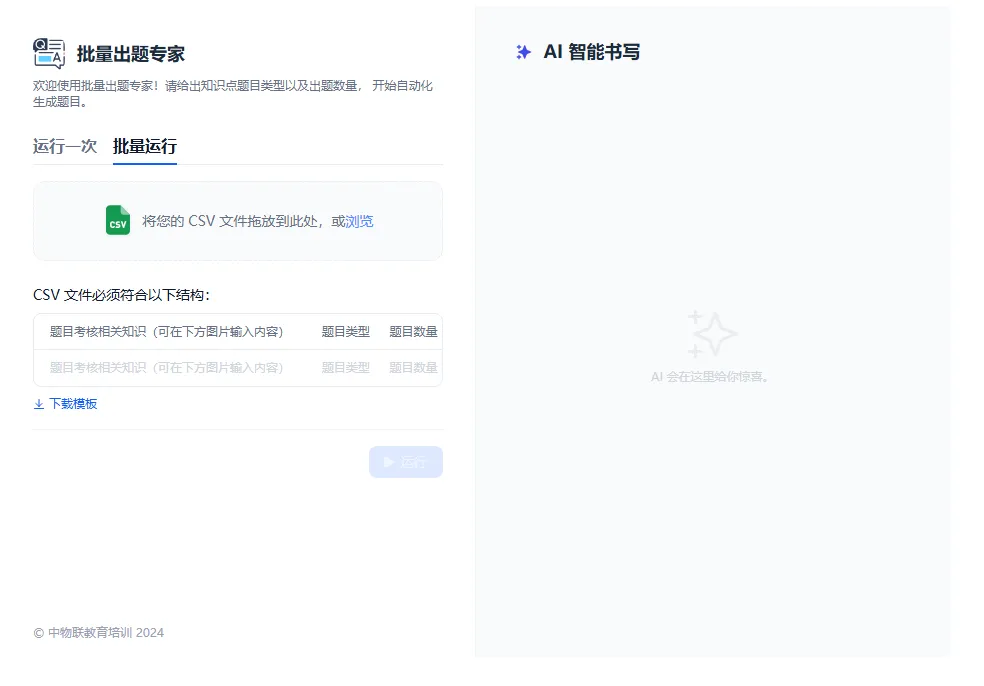
2、点击“下载模板”(蓝色字体),获取具体csv表格文件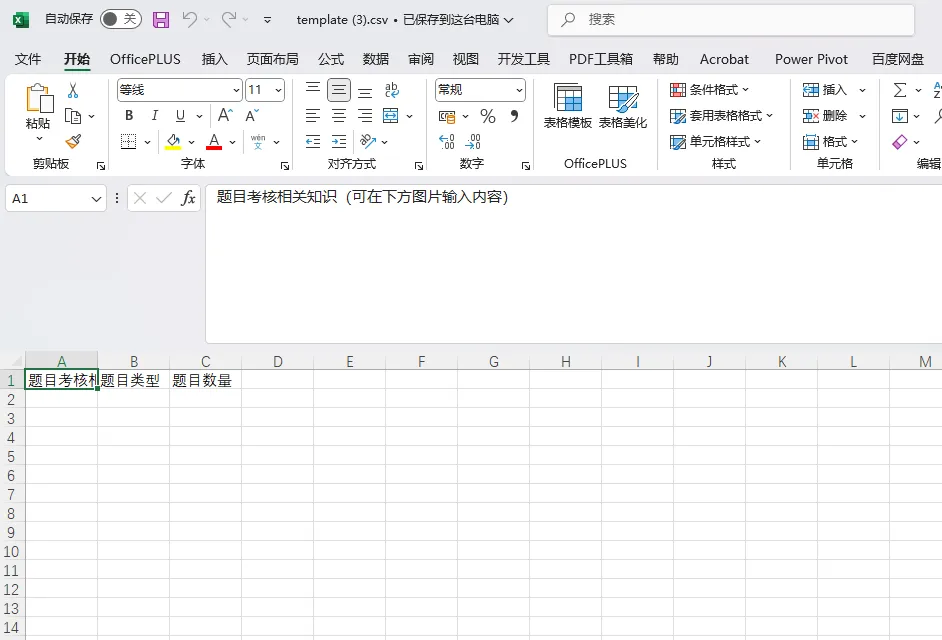
3、在指定维度列输入具体内容(具体内容必须符合输入要求),填写完成后点击保存(记住存储位置)
*注意,请将csv文件保存为UTF-8格式
4、在应用界面点击“浏览”,将刚刚保存的csv文件上传,点击右下角的“运行”按钮,即可实现批量运行。
5、批量运行后的结果可以下载到本地,生成json格式的数据,以csv表格形式呈现。可以将json格式的数据通过python代码转换成普通文本格式。
json转普通文本的具体步骤
以批量出题专家为例
批量运行后的出题结果,下载到本地(excel形式),结果以json格式输出。

为了便于高质量新题批量导入题库,利用python代码将json格式输出的题目转为普通文本(word),转换代码如下
import pandas as pd
from docx import Document
import json
import re
# 读取Excel文件
excel_file = '供应链管理师.xlsx' # 替换为你的Excel文件路径
sheet_name = 'result (2)' # 替换为你的表单名称
df = pd.read_excel(excel_file, sheet_name=sheet_name)
# 创建Word文档
doc = Document()
doc.add_heading('Parsed and Cleaned JSON Data from Excel', 0)
# 函数:去除Markdown语法
def markdown_to_text(text):
# 替换标题 # 和 ##
text = re.sub(r'#+ ', '', text)
# 替换粗体 **bold** 和斜体 *italic*
text = re.sub(r'\*\*(.*?)\*\*', r'\1', text)
text = re.sub(r'\*(.*?)\*', r'\1', text)
# 替换链接 [text](URL)
text = re.sub(r'\[(.*?)\]\((.*?)\)', r'\1 (\2)', text)
# 处理列表符号 (-, *, 1.),保留为普通文本
text = re.sub(r'^[\*\-\+] ', '', text, flags=re.MULTILINE)
text = re.sub(r'^\d+\. ', '', text, flags=re.MULTILINE)
return text
# 遍历每一行,将JSON格式数据解析并转换为普通文本
for index, row in df.iterrows():
json_data = row.iloc[3] # 假设JSON数据在第一列,调整列索引为你的实际情况
try:
# 尝试将JSON数据解析为字典或列表
json_object = json.loads(json_data)
# 递归处理字典或列表,并将其转换为可读文本格式
def json_to_text(json_obj, indent=0):
text_lines = []
if isinstance(json_obj, dict):
for key, value in json_obj.items():
text_lines.append(" " * indent + f"{key}:")
text_lines.extend(json_to_text(value, indent + 4))
elif isinstance(json_obj, list):
for item in json_obj:
text_lines.extend(json_to_text(item, indent + 4))
else:
# 如果是字符串,先去掉Markdown语法
if isinstance(json_obj, str):
json_obj = markdown_to_text(json_obj)
text_lines.append(" " * indent + str(json_obj))
return text_lines
formatted_text = "\n".join(json_to_text(json_object))
except json.JSONDecodeError:
# 如果解析失败,保留原始JSON数据并处理Markdown
formatted_text = markdown_to_text(json_data)
# 添加到Word文档
doc.add_paragraph(formatted_text)
# 保存Word文件
word_file = '供应链管理师试题.docx' # 输出Word文件路径
doc.save(word_file)
print(f'Word文件已成功保存为 {word_file}')
处理后的结果
